
エイト・クイーンのプログラムアーカイブ
Bash、Lua、C、Java、Python、CUDAまで!
https://github.com/suzukiiichiro/N-Queens
CUDAセットアップ
昔は面倒なことだったのです。
AWS Amazon Linux 2 にCUDA 10環境を作る
https://qiita.com/navitime_tech/items/093206ffda0e6e3125ea
<<はい、バッサリ省略>>
最近ではAWS(アマゾンウェブサービス)でNVIDIA CUDAインスタンスを立てれば、それだけで環境はすべて整っていますので、5分で開発を開始できます。
AWSのGPUインスタンスでCUDAを動かす
https://qiita.com/navitime_tech/items/0a8073347c21800f1cad
料金とかきになるところです。以下を参考にして下さい。
AWSのGPUインスタンス構築 値段を抑えて最短で構築する
https://qiita.com/Brutus/items/72d39c50b458e00925e9
確認方法ですが、ログインして
$ nvcc --version
とかやってなにか出てくればオッケーです。
NQueens2$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Jul_11_02:31:28_PDT_2023
Cuda compilation tools, release 12.2, V12.2.128
Build cuda_12.2.r12.2/compiler.33053471_0
NQueens2$
以下のコマンドで、稼働時のリアルタイム監視が可能です。
$ watch nvidia-smi
ということでCUDAでGPUプログラミング
CUDAでGPUプログラミングを行うわけですが、
・C言語系で記述します。
・コンパイルは $nvcc で行います。
・実行はファイルは./a.out で実行できます。
・エイトクイーンで言えば、C言語で記述されたプログラムよりも、-pthredで記述された並列処理のほうが10倍高速
・エイトクイーンで言えば、C言語の-pthredで記述されたプログラムよりも、$nvcc でGPU実行した並列処理のほうが10倍高速(少なくとも)
です。
CUDAで並列処理を行う場所
ここが一番重要で、プログラムの数だけ最適なやり方があると思うので、こういうときにはこういうふうにするといったルールは断定することはできませんが、
・猛烈に再帰、またはforでループしている箇所
が特定できれば底の部分をCUDA適用すると良いと思います。
物理サーバーで並列処理する場合との違い
物理サーバーに分解して並列処理することのメリットは十二分にあります。
もちろん、物理サーバーに分解せずに、そこの分解部分をCUDAで分解実行しても良いわけです。
苦手なこと
並列処理の分解部分が小さくてたくさんある場合は、CUDA向けです。
並列処理の分解部分が大きい場合は、物理サーバーで分解並列処理しておいた上で、さらに細かく分解できる処理があれば、その部分をCUDAで並列処理を行うと良いでしょう。
難しいこと
並列処理させること自体は難しくはありませんが、並列処理を実行した結果を集計したり、集計した結果それぞれを利用して次の処理に渡したりする場合は、同期処理、待機処理などを行う必要があり、その都度、Googleで何日も、下手をすると何週間も調べることになります。
CUDA
実行
実行は以下の4種類です。
1.シングルスレッドで再帰
こちらは以下のメソッドを呼び出し再帰実行します。
// ビットマップ 再帰版
void bitmap_R(unsigned int size,unsigned int row,unsigned int left,unsigned int down, unsigned int right)
$ nvcc 01CUDA_Bitmap.cu && ./a.out -r
2.シングルスレッドで非再帰
こちらは以下のメソッドを呼び出し非再帰実行します
// ビットマップ 非再帰版
void bitmap_NR(unsigned int size,int row)
$ nvcc 01CUDA_Bitmap.cu && ./a.out -c
3.シングルスレッドのGPU
こちらはInitCUDA()を通過後、以下のメソッドを呼び出します。
シングルスレッドで動作します。
// クイーンの効きを判定して解を返す
host device
long bitmap_solve_nodeLayer(int size,long left,long down,long right)
$ nvcc 01CUDA_Bitmap.cu && ./a.out -g
3の必要性は、4を開発している間、問題点を局所化するためです。
3の解がきちんと出力していれば、他の箇所に問題があると特定することが目的です。
4.マルチスレッドのGPU
こちらはInitCUDA()を通過後、以下のメソッドを呼び出します。
マルチスレッドで動作します。
$ nvcc 01CUDA_Bitmap.cu && ./a.out -n
次の項では、4について具体的に説明します。
関数の説明
InitCUDA()を通過後、以下のメソッドを順次辿って実行されます。
// 【GPU ビットマップ】ノードレイヤーの作成
void bitmap_build_nodeLayer(int size)
// k 番目のレイヤのすべてのノードを含むベクトルを返す。
std::vector<long> kLayer_nodeLayer(int size,int k)
// ノードをk番目のレイヤーのノードで埋める
long kLayer_nodeLayer(int size,std::vector<long>& nodes, int k, long left, long down, long right)
// 0以外のbitをカウント
int countBits_nodeLayer(long n)
// i 番目のメンバを i 番目の部分木の解で埋める
__global__
void dim_nodeLayer(int size,long* nodes, long* solutions, int numElements)
// クイーンの効きを判定して解を返す
__host__ __device__
long bitmap_solve_nodeLayer(int size,long left,long down,long right)
【GPU ビットマップ】ノードレイヤーの作成
void bitmap_build_nodeLayer(int size)
以下でレイヤーの数を指定します。
Nが増えればレイヤーは枯渇します。
Nが16まではレイヤーは4で足りますが、以降、レイヤーは、5,6と増やす必要があり、レイヤーが増えることによって、速度は加速度的に遅くなります。
ノードレイヤーの考え方はスマートではありますが、Nの最大化と高速化を求める場合は限界がまもなくおとずれるロジックです。
今の段階では、レイヤー4で進めていきます。
// ツリーの3番目のレイヤーにあるノード
//(それぞれ連続する3つの数字でエンコードされる)のベクトル。
// レイヤー2以降はノードの数が均等なので、対称性を利用できる。
// レイヤ4には十分なノードがある(N16の場合、9844)。
std::vector<long> nodes = kLayer_nodeLayer(size,4);
以下で、ノードごとの解を保存する配列を用意します。
ノードレイヤーの特性として、ノードの半分だけを利用して解を出すことができます。これはミラーのイメージでよいです。
// デバイス出力の割り当て
long* deviceSolutions = NULL;
// 必要なのはノードの半分だけで、各ノードは3つの整数で符号化される。
int numSolutions = nodes.size() / 6;
size_t solutionSize = numSolutions * sizeof(long);
cudaMalloc((void**)&deviceSolutions, solutionSize);
以下で、CUDAカーネルを起動します。
CUDAで並列処理したい関数 <<< 並列処理の指定 >>>( 関数パラメータ)
関数パラメータは、構造体にひとまとめにするよりも、ばらして渡す方がメモリ消費的に良いとされています。
// CUDAカーネルを起動する。
int threadsPerBlock = 256;
int blocksPerGrid = (numSolutions + threadsPerBlock - 1) / threadsPerBlock;
dim_nodeLayer <<<blocksPerGrid, threadsPerBlock >>> (size,deviceNodes, deviceSolutions, numSolutions);
CUDAの実行が終わったら、デバイス側に保存されている配列をcudaMemcpy()でホスト側にコピーします。
// 結果をホストにコピー
long* hostSolutions = (long*)malloc(solutionSize);
cudaMemcpy(hostSolutions, deviceSolutions, solutionSize, cudaMemcpyDeviceToHost);
ホスト側にコピーした配列をスレッドの数だけforで回して、解を一つ一つ取り出して集計します。
// 部分解を加算し、結果を表示する。
long solutions = 0;
for (long i = 0; i < numSolutions; i++) {
solutions += 2*hostSolutions[i]; // Symmetry
}
// 出力
TOTAL=solutions;
メモ
int numSolutions = nodes.size() / 6;
3個で1セットなので/3 さらにnodesの2分の1だけ実行すればミラーになるので/6
solutions += 2*hostSolutions[i]; // Symmetry
GPUごとのTOTALを集計している。ミラー分最後に2倍する
k 番目のレイヤのすべてのノードを含むベクトルを返す。
std::vector<long> kLayer_nodeLayer(int size,int k)
こちらの関数は、kLayer_nodeLayer()を使って、必要なノードを埋める処理をします。ようするに、Nクイーンの当たり判定をすべて行いノードを作成するということになります。
ノードレイヤーが遅い理由は、Nクイーンの処理を、当たり判定と本番確定の2回行っていることです。
メモ
GPUで並列実行するためのleft,right,downを作成する
kLayer_nodeLayer(size,4)
第2引数の4は4行目までnqueenを実行し、それまでのleft,down,rightをnodes配列に格納する
nodesはベクター配列で構造体でもなんでも格納できる
push_backで追加。
nodes配列は3個で1セットleft,dwon,rightの情報を同じ配列に格納する
[0]left[1]down[2]right
i 番目のメンバを i 番目の部分木の解で埋める
__global__
void dim_nodeLayer(int size,long* nodes, long* solutions, int numElements)
こちらで、CUDAによって並列処理された一つ一つのスレッドがNクイーンを実行して、その結果をcounterに追記格納し、返却します。
クイーンの効きを判定して解を返す
__host__ __device__
long bitmap_solve_nodeLayer(int size,long left,long down,long right)
こちらのメソッドは -g オプションで起動したときのメソッドですが、いわゆるNクイーンのメインメソッドとなります。
メモ
down==maskが最終行までクイーンを置けた状態
ビットだとクイーンを置けない場所に1が立つ
downだとクイーンを置いた場所に1が立つ
maskは、size分1が立っているもの
n8だと11111111
downはクイーンが配置されるたびに配置された列に1が立って行くので最終行までクイーンを置くと全列に1が立った状態になりmaskと同じ内容になる
i 番目のメンバを i 番目の部分木の解で埋める
global
void dim_nodeLayer(int size,long* nodes, long* solutions, int numElements)
メモ
GPU並列処理
bitmap_solve_nodeLayerを再帰呼び出しし、counter(最終行までクイーンを置けると+1)をsolutionsに格納する
solutionsは配列でGPUのステップ数分ある
エイトクイーン
ここからは、ビットマップについて少し詳細に説明しておきたいと思います。
ビットマップ
N×NのチェスボードのN個のクイーンの配置を、bitwise(ビット)で表したものがbitmap(ビットマップ)です。
ビットマップの特徴
斜め方向にクイーンを配置したかどうかを、left down right といった bit フラグで表します。
大きなメリットは、
1.ビットマップであれば、シフト(<<1 ,>>1)により高速にデータを移動できる。
2.配置フラグといったフラグ配列では、データの移動に O(N) の時間がかかるが、ビットマップであれば O(1)ですむ。
3.フラグ配列のように斜め方向に 2*N-1 の要素を用意する必要はなく Nビットで充分たりる。
4.ビットは初期値が0なので扱いやすい
デメリットとしては
2進数と10進数により難読化が極まっている。
ビットマップを言葉で説明すると・・・
4x4のチェス盤を使ってみましょう。
チェス盤の各行は1つの2進数で表されますが、これは単なるビットの並びです。
ある行の一番左のマスにクイーンが置かれた場合、その行は8という数字で表されます。
+-+-+-+-+
|Q| | | | 1000
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
この列の一番左には1があるので、2進数では1000となります。
左から3番目のマスにクイーンが置かれた場合、その列は2、つまり0010で表されます。
+-+-+-+-+
| | |Q| | 0010
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
1: 0001
+-+-+-+-+
| | | |Q|
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
2: 0010
+-+-+-+-+
| | |Q| |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
4: 0100
+-+-+-+-+
| |Q| | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
8: 1000
+-+-+-+-+
|Q| | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
1、2、4、8以外の数字は、
9→1001
+-+-+-+-+
|Q| | |Q|
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
15→1111
+-+-+-+-+
|Q|Q|Q|Q|
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
のように、2つ以上のマスの占有を表すのに使うことができます。
コンフリクトの列が5(0101)の場合、左から1番目と3番目のマスが、他のクイーンとぶつからない唯一の空きマスであることを示し、この2マスに次のクイーンを配置することになります。
5→0101
+-+-+-+-+
| |Q| |Q|
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
| | | | |
+-+-+-+-+
ビットマップ!
N5のボードレイアウト
4 2 0 3 1 ↓ bitmapで表現
+-+-+-+-+-+
| | | | |O| 00001
+-+-+-+-+-+
| | |O| | | 00100
+-+-+-+-+-+
|O| | | | | 10000
+-+-+-+-+-+
| | | |O| | 00010
+-+-+-+-+-+
| |O| | | | 01000
+-+-+-+-+-+
各行(row)の状態をbitwise(ビットワイズ)で表現します。
クイーンが置いてある位置のbit(ビット)をON(1)にします。
バックトラッキングは行(row=0)から下に向かって順に、クイーンが配置できた場所のbitをON(1)にして、その後rowが一つインクリメントします。
4 ↓ bitmapで表現
+-+-+-+-+-+
| | | | |O| 00001
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
4 2 ↓ bitmapで表現
+-+-+-+-+-+
| | | | |O| 00001
+-+-+-+-+-+
| | |O| | | 00100
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
4 2 0 ↓ bitmapで表現
+-+-+-+-+-+
| | | | |O| 00001
+-+-+-+-+-+
| | |O| | | 00100
+-+-+-+-+-+
|O| | | | | 10000
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
4 2 0 3 ↓ bitmapで表現
+-+-+-+-+-+
| | | | |O| 00001
+-+-+-+-+-+
| | |O| | | 00100
+-+-+-+-+-+
|O| | | | | 10000
+-+-+-+-+-+
| | | |O| | 00010
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
4 2 0 3 1 ↓ bitmapで表現
+-+-+-+-+-+
| | | | |O| 00001
+-+-+-+-+-+
| | |O| | | 00100
+-+-+-+-+-+
|O| | | | | 10000
+-+-+-+-+-+
| | | |O| | 00010
+-+-+-+-+-+
| |O| | | | 01000
+-+-+-+-+-+
効き筋
次に、効き筋をチェックするためにさらに3つのビットフィールドを用意します。
left
+-+-+-+-+-+
| | | |Q| |
+-+-+-+-+-+
| | |L| | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
down
+-+-+-+-+-+
| | | |Q| |
+-+-+-+-+-+
| | | |D| |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
right
+-+-+-+-+-+
| | | |Q| |
+-+-+-+-+-+
| | | | |R|
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
左下に効き筋が進む(left)、真下に効き筋が進む(down)、右下に効き筋が進む(right)3つです。
その3つのビットフィールドをそれぞれ、left, down, right と呼ぶことにします。
まずは row0 にクイーンを配置します。
Qの配置
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
次に、row0 のビットフィールドから row+1 番目のビットフィールド、ようするにひとつ下の row1 に探索を進め、
Qの配置
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
| | | | | | ←ここ
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
row0のビットフィールドでクイーンが配置されている bit と、
Qの配置
+-+-+-+-+-+
| | | |Q| | 00010 = bit
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
3つのビット left down right を使って、効き筋をチェックします。
効き筋は「OR演算」を使います。
ビット演算に関しては以下のリンクがおすすめです。
ビット演算入門
leftはひとつ左に
left
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
| | |L| | | 00100
+-+-+-+-+-+
downはそのまま下に、
down
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
| | | |D| | 00010
+-+-+-+-+-+
rightはひとつ右へ
right
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
| | | | |R| 00001
+-+-+-+-+-+
こういったロジックで row+1 番目の効き筋をチェックします。
bit(ビット)
クイーンの位置は「Q」です。
Qを配置した場合、そのposition(場所)はbitで表します。
bit(ビット)には、クイーンが配置されるとその位置が格納されるわけです。
以下の場合、bitは 00010 となります。
row0にQが配置された
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
ここでbitの操作が複雑となる原因のひとつ、
「00010」というクイーンの位置情報は、そのままbitに格納されるのではありません。
bitには00010 という場所の情報が格納されるわけですが、
「00001」の場合は「 1」
「00010」の場合は「 2」
「00100」の場合は「 4」
「01000」の場合は「 8」
「10000」の場合は「16」
が格納されることになります。
「はぁ?」
まず、
「00001」という並びは0と1でなりたつ表現方法で「2進数」といいます。
また、10で桁上りをする表現方法はおなじみの「10進数」といいます。
00010 2進数
2 10進数 (00010を10進数にすると 2 になる)
2進数を10進数に置き換える早見表
10進数 128 64 32 16 8 4 2 1
2進数 0 0 0 0 0 0 0 0
2進数 00010 を10進数に置き換えた値が知りたいは、早見表を使うと10進数では 4 となります。
2進数を10進数に置き換える早見表
10進数 16 8 4 2 1
2進数 0 0 1 0 0
ということで、クイーンの位置が 00100 の場合は、4 が bitに格納されます。
bashでは2進数を10進数に変換して出力する方法が用意されています。
bash-3.2$ echo $(( 2#00001 ))
1
bash-3.2$ echo $(( 2#00010 ))
2
bash-3.2$ echo $(( 2#00100 ))
4
bash-3.2$ echo $(( 2#01000 ))
8
bash-3.2$ echo $(( 2#10000 ))
16
bash-3.2$
#(シャープ)の前の数字は2進数であることを示しています。
2進数 00100 の10進数の値が知りたければ、次のようにします。
bash-3.2$ echo $(( 2#00100 ))
4
余談ですが(余談ということでもないのですが)、
Nが8の場合で、00010000 というクイーン配置の場合
10進数 128 64 32 16 8 4 2 1
2進数 0 0 0 1 0 0 0 0
早見表の通り、10進数では「16」となります。
当然、bashでも求めることができます。
bash-3.2$ echo $(( 2#00010000 ))
16
さらに余談ですが(これは本当に余談)、ビットフィールドに複数のbitがON(1)である場合、例えば「00101010」のような場合は、以下のように計算します。
((一行にクイーンが3つもある!!)
00101010
10進数 128 64 32 16 8 4 2 1
2進数 0 0 1 0 1 0 1 0
この場合は、bitが立っている(と言います)10進数の値をを足し合わせることで表現できます。
ビットが立っている(1となっている)のは、32と8と2ですから、
32 + 8 + 2 = 42
となります。
bashでも確認してみます。
bash-3.2$ echo $(( 2#00101010 ))
42
おお、いい感じですね。着いてきていますか?
Qの位置を確認
では、まずはQのposition(位置)を確認します。
Q
+-+-+-+-+-+
| | | |Q| | 00010=bit といいます。
+-+-+-+-+-+
| | | | | |
+-+-+-+-+-+
Qのpositionは 00010 です。
10進数では以下の早見表で見つけると良いです。
Qが置かれているbitの値は「00010」です
10進数 16 8 4 2 1
2進数 0 0 0 1 0
10進数では「2」ですね。
まず、Qのpositionがわかりました。
Qのpositionをbitと言います。
通常、bitは変数名もbitとします。
bit = Q = 2#00010 = 2
row + 1 のleftの効き筋をチェック)してみます
left
+-+-+-+-+-+
| | | |Q| | 00010 (`bit`)
+-+-+-+-+-+
| | |L| | | ←ここ
+-+-+-+-+-+
「L」は「Q」の真下(row+1)を左に一つずらした位置となります。
ビット演算では以下のようになります。Lはleftを表しています。
( left | bit)<<1
( left | bit) といった表現を「OR演算」と言います。
left にはこの段階では値が何も入っていませんので「0」となります。
要するに初期値「0」のまま計算します。
前項で求めたとおり、Qであるbitは以下の通りでした。
bit = Q = 2#00010 = 2
leftは、初期値「0」な訳ですから、
( left | bit )
( 0 | 2 )
という計算式になります。
bashで計算してみましょう。
bash-3.2$ echo $(( (2|0) ))
2
bash-3.2$
「2」とでました。
さらに左に一つシフト(«1)してみます。
こうなりますね。
( left | bit )<<1
( 0 | 2 )<<1
bashで計算してみます。
bash-3.2$ echo $(( (2|0)<<1 ))
4
bash-3.2$
「4」とでました。
「4」の2進数はなんでしょう?
さっそく早見表で確認しましょう。
10進数 16 8 4 2 1
2進数 0 0 1 0 0
00100 という事ですね。
Qが置かれている場所が「00010」で、
Lは「00100」となったわけです。
図で表すと以下のとおりです。
left
+-+-+-+-+-+
| | | |Q| | 00010 (bit)
+-+-+-+-+-+
| | |L| | | 00100 (left|bit)<<1
+-+-+-+-+-+
ということで、Qの位置から左に一つずれているのがわかります。
Qを配置してleftを使って左下の効きを簡単に求めることができました。
left = ( left | bit )<<1
00100 = ( 0 | 00010 )<<1
4 = ( 0 | 2 )<<1
row0にある Q の位置「00010」の、ひとつ下の row1 のleftの効き筋は (left|bit)<<1 という計算式を用いて、「00100」となりました。
言い換えると、Qの位置をbitにして、(left|bit)<<1とすることで、ビットの位置を一つ左にシフトして、Qのleftの効き筋を求めることができたということになります。
row + 1 のdownの効き筋をチェック)してみます
leftの場合は、( left | bit )«1 ということをしてQの位置から左に一つずらした位置を求めました。
downはleftのように左に一つずらしたりする必要はありません。
Qの位置からましたに下ろすだけですから値は同じなのです。
down
+-+-+-+-+-+
| | | |Q| | 00010
+-+-+-+-+-+
| | | |D| | 00010 (down|bit)
+-+-+-+-+-+
down = ( down | bit )
00010 = ( 0 | 00010 )
2 = ( 0 | 2 )
bashでも確認してみます。
bash-3.2$ echo $(( (0|2) ))
2
bash-3.2$
down は 2#00010 ですので 2 です。
ここまでをまとめると以下のとおりです。
bit = Q = 2#00010 = 2
10進数 16 8 4 2 1
2進数 0 0 0 1 0
left = (left|bit)<<1 = 2#00100 = 4
10進数 16 8 4 2 1
2進数 0 0 1 0 0
down = (down|bit) = 2#00010 = 2
10進数 16 8 4 2 1
2進数 0 0 0 1 0
row + 1 のrightの効き筋をチェック
rightはleft同様にシフトするわけですが、今度は右へシフトします。
right
+-+-+-+-+-+
| | | |Q| | 00010 (bit)
+-+-+-+-+-+
| | | | |R| 00001 (R) (right|bit)>>1
+-+-+-+-+-+
right = ( right | bit )>>1
00010 = ( 0 | 00010 )>>1
1 = ( 0 | 2 )>>1
bashでも確認してみます。
bash-3.2$ echo $(( (0|2)>>1 ))
1
bash-3.2$
ここまでをまとめると以下のとおりです。
bit = Q = 2#00010 = 2
10進数 16 8 4 2 1
2進数 0 0 0 1 0
left = (left|bit)<<1 = 2#00100 = 4
10進数 16 8 4 2 1
2進数 0 0 1 0 0
down = (down|bit) = 2#00010 = 2
10進数 16 8 4 2 1
2進数 0 0 0 1 0
right =(right|bit)>>1= 2#00001 = 1
10進数 16 8 4 2 1
2進数 0 0 0 0 1
マスクビット
ビットの使い方として最も多いものの 1 つがマスクビットです。なじみの深いもので言えば、IPアドレスのマスクビットや割り込み制御のマスクビットなどが挙げられます。多種多様な場面で使用されるマスクビットですが、基本的なアイディアは共通で、
・複数のフラグをまとめて立てる
・複数のフラグをまとめて消す
・必要な情報だけを取り出すために、マスクした部分の情報のみを取り出す
といったものを効率良く実現するものです。
現在のフラグ状態を表すビットを bit として、マスクビットを mask としたとき
| 概要 | 実装 |
|---|---|
| mask で表された部分のフラグをまとめて立てる | bit |= mask |
| mask で表された部分のフラグをまとめて消す | bit &= ~mask |
| mask で表された部分の情報のみを取り出したもの | bit & mask |
| mask で表された部分のどれかのフラグが立っているかどうか | if (bit & mask) |
| mask で表された部分のすべてのフラグが立っているかどうか | if ((bit & mask) == mask) |
mask(マスク)
ここまでで3つのフラグを用いてQの効き筋を求めてきました。
left+down+right
+-+-+-+-+-+
| | | |Q| | 00010 (bit)
+-+-+-+-+-+
| | |L|D|R| 00111 (left|down|right)
+-+-+-+-+-+
3箇所の効き筋を演算子を使うと
(left|down|right)
となり、こうした表現を「OR演算」と言います。
さて、row + 1 番目のビットフィールドを探索して、left down right の3つのbitフラグを「OR演算」したビットフィールドを作りました。
ON(1)になっている位置は効き筋に当たるので置くことができません。
rowにQを配置して、
+-+-+-+-+-+ row
| | | |Q| | 0 今、自分はここにいて
+-+-+-+-+-+
| | | | | | 1
+-+-+-+-+-+
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
自分がいる row の一つしたの「row+1」のビットフィールドを探索するために、
+-+-+-+-+-+ row
| | | |Q| | 0
+-+-+-+-+-+
|*|*|*|*|*| 1 この行(row)を順番に探索する
+-+-+-+-+-+
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
left down right の3つのフラグを使って、効きををチェックします。
left down right のいずれかがON(1)になっていたら効き筋に当たるから、その場所にはクイーンは配置できませんね。
という意味になります。
+-+-+-+-+-+ row
| | | |Q| | 0 bit = Q = 2#00010 = 2
+-+-+-+-+-+ left = (left|bit)<<1 = 2#00100 = 4
|*|*|L|D|R| 1 down = (down|bit) = 2#00010 = 2
+-+-+-+-+-+ right= (right|bit)>>1= 2#00001 = 1
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
そこで、上記の図の2箇所(アスタリスク*の場所)がクイーンを配置することがが可能です。
この2箇所のアスタリスクは場所を簡単に得ることができます。
以下の通り、left は4 down は2 right は1 です。
bit = Q = 2#00010 = 2
left = (left|bit)<<1 = 2#00100 = 4
down = (down|bit) = 2#00010 = 2
right= (right|bit)>>1= 2#00001 = 1
効き筋 (left|down|right) は、次のように求めることができます。
(4|2|1)
と、なります。
bashで確認すると以下のとおりです。
bash-3.2$ echo $(( (4|2|1) ))
7
bash-3.2$
「7」となりました。これを2進数で表すと
bash-3.2$ bc <<<"ibase10;obase=2;7"
111
bash-3.2$
「111」ですから5ビットにすると
2#00111 となります。
そこで、以下のアスタリスクの部分を求めるには「反転」という演算をおこないます。
+-+-+-+-+-+ row
| | | |Q| | 0 bit = Q = 2#00010 = 2
+-+-+-+-+-+ left = (left|bit)<<1 = 2#00100 = 4
|*|*|L|D|R| 1 down = (down|bit) = 2#00010 = 2
+-+-+-+-+-+ right= (right|bit)>>1= 2#00001 = 1
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
ここで、2#11000を求めることができれば、それがクイーンを配置することができる場所ということになります。
2#11000 をbashで求めると24になります。
bash-3.2$ echo $(( 2#11000 ))
24
bash-3.2$
演算で求める場合は、「反転」という演算を使います。
(L|D|R) の 反転はチルダ「〜」を使います。
~(L|D|R)
では、先に求めた「24」になるかを確認してみましょう。
bash-3.2$ echo $(( (4|2|1) ))
7
bash-3.2$ echo $(( ~(4|2|1) ))
-8
bash-3.2$
なりませんね。。。
ここでmask(マスク)を使います。
maskとは、ビットフィールドのビットをすべて立てたものです。
+-+-+-+-+-+ row
| | | |Q| | 0
+-+-+-+-+-+
|M|M|M|M|M| 1 mask=2#11111
+-+-+-+-+-+
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
このmaskは簡単に求めることができます。
mask=(1<<size)-1;
N5の場合、2進数で求めると「31」になります。
bash-3.2$ echo $(( 2#11111 ))
31
maskは、size=5 ( 1<<size )-1 という計算式で求めることができます。
bash-3.2$ echo $(( (1<<5)-1 ))
31
このmaskを使って
1.left down rightの3つのビットを使って効きの場所を特定
(left|down|right)
+-+-+-+-+-+ row
| | | |Q| | 0
+-+-+-+-+-+
| | |L|D|R| 1 2#00111
+-+-+-+-+-+
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
2.反転させる
# 2#00111
~(left|down|right) = -8
# 2#11000
2.maskですべての配置箇所のビットをON(1)にする
maskを使ってすべてのビットを立てる
size=5;
mask=$(( (1<<size)-1 ));
+-+-+-+-+-+ row
| | | |Q| | 0
+-+-+-+-+-+
|M|M|M|M|M| 1 2#11111 = 31
+-+-+-+-+-+
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
3.maskから~(left|down|right)を間引いた値をbitmapに格納
# クイーンが配置可能な位置を表す
bitmap=$(( mask&~(left|down|right) ))
+-+-+-+-+-+ row
| | | |Q| | 0
+-+-+-+-+-+
|1|1|0|0|0| 1 2#11000 = 24
+-+-+-+-+-+
| | | | | | 2
+-+-+-+-+-+
| | | | | | 3
+-+-+-+-+-+
| | | | | | 4
+-+-+-+-+-+
(left|down|right) 2#00111
~(left|down|right) 2#11000
mask 2#11111
----------------------------
AND 2#11000 24 bitmap
おおお、24になりました。
bitmapには24が格納されるわけです。
これで効きのない場所を特定することができました。
1がクイーンを配置できる場所、いわゆる効き筋に当たらない場所ということになります。
あとは、効き筋に当たらない場所を順番にQを置いて行けばよいということになります。
順番にひとつひとつつまみ出して行く方法は後述します。
ここまでの処理をbashで書くと以下の通りになります。
#!/usr/bin/bash
mask=31; # 2#11111
left=4; # 2#00100
down=2; # 2#00010
right=1; # 2#00001
# (left|down|right)を反転させてmaskで間引く
# クイーンが配置可能な位置を表す
bitmap=$(( mask&~(left|down|right) ))
echo "$bitmap" # 24
# 間引いた10進数を2進数にして確認
bc<<<"ibase=10;obase=2;$bitmap"
# 11000
実行結果は以下のとおりです。
bash-3.2$ bash masktest.sh
11000
ビットマップで肝となるところを重点的に
// クイーンが配置可能な位置を表す
bitmap=mask&~(left|down|right);
// 一番右のビットを取り出す
bit=bitmap&-bitmap;
// 配置可能なパターンが一つずつ取り出される
bitmap=bitmap&~bit;
// Qを配置
board[row]=bit;
// 再帰
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);
普通に書くとこうなります。
mask=(1<<size)-1;
bitmap=mask&~(left|down|right);
while(bitmap){
bit=bitmap&-bitmap;// 一番右のビットを取り出す
bitmap=bitmap&~bit;// 配置可能なパターンが一つずつ取り出される
board[row]=bit;// Qを配置
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);// 再帰
}
forで一行にまとめることができます。これは非常にトリッキーです。
for(unsigned int bitmap=mask&~(left|down|right);bitmap;bitmap=bitmap&~bit){
bit=bitmap&-bitmap;
board[row]=bit;
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);
}
bitmap=mask&~(left|down|right)
クイーンが配置可能な位置を表す
bitmap=mask&~(left|down|right)
bit=-bitmap & -bitmap
while中の各繰り返しで、bit に、配置できる可能性と配置できない可能性をAND演算した結果をbitにセットしています。この結果、bit は、bitmap の最下位ビットを除いて、すべて0に設定し、Qを配置します。
もう少し噛み砕いて説明すると、単に最初の非ゼロビット(つまり最初に利用できる場所である1)を bit という変数に格納するだけです。
その bit (ビットが0010なら3列目)は、次のクイーンを置く場所となります。
つまり、bitmapの列を0にすることで、現在の位置が「取られた」ことを示すだけです。
こうすることで、whileループ中で、「取られた」場所を再度試す必要がなくなるということになります。
bit=-bitmap & -bitmap
bitmap=bitmap&~bit
配置可能なパターンが一つずつ取り出され、bitmap の最下位ビットを開放、次のループに備え、新しい最下位ビットを探索、再帰的な呼び出しを行い、次の行のビットフィールドであるbitmap を更新します。
bit には、Qの場所を表す1 が1つだけ入ったビットフィールが格納されています。
渡された競合情報とOR演算 することで、再帰呼び出しの競合候補として追加されます。
bitmap=bitmap&~bit
board[row]=bit
要するにQを配置するわけです。
board[row]=bit
bitmap_R(size,row+1,(left|bit)«1,down|bit,(right|bit)»1);
ソースの中も最も混乱する行だと思います。
演算子 >>1 と 1<< は、ビットフィールド列すべてのビットをそれぞれ右、または左に1桁移動させるだけです。
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);
つまり、(left|bit)<<1 を呼ぶと、「leftとbitをOR演算で結合し、結果のすべてを1桁左に移動させる」という意味になります。
具体的には、left が 0001 (現在の行の4列目を通る右上から左下までの対角線が占有されていることを意味する)、bit が 0100(現在の行の2列目にクイーンを置く予定であることを意味する)の場合、(left|bit) の結果は 0101 (現在の行の2列目にクイーンを置いた後、右上から左下までの対角線2本目と4本目が占有されることになります)。
ここで、<< 演算子を加えると、(left|bit)<<1 となり、前の箇条書きで計算した 0101 を、すべて左に1つずつ移動させます。したがって、結果は 1010 となります。
さて、ここからが本当に難しいところなのですが、bitmap_R を再度呼び出す前に、なぜ1桁ずつ移動させるのでしょうか。
row が一番上の行から始まり、下に移動する場合、新しい行に移動するたびに、「占有対角線」のトラッキング変数である left と right を最新に保つ必要があります。
そこで、下のボートレイアウトを例にとると、
+-+-+-+-+ row
| | |Q| | 0
+-+-+-+-+
|Q| | | | 1
+-+-+-+-+
| | | |Q| 2
+-+-+-+-+
| |Q| | | 3
+-+-+-+-+
最上段3列目にクイーンを置くと、その瞬間の left down right はそれぞれ0010、0010、0010となる。
しかし、再びbitmap_Rを呼び出して次の行に進むと、2行目では、2列目、3列目、4列目のすべてが、これまでに配置した1つのクイーンによって「攻撃されている」ことがわかります。
具体的には、3列目が占領され(downは0010)、2行目の4列目を通る左上から右下の対角線が占領され(だからrightは0001)、2行目の2列目を通る右上から左下の対角線が占領されています(だからleftは0100)。
+-+-+-+-+ row
| | |Q| | 0
+-+-+-+-+
| |x|x|x| 1
+-+-+-+-+
| | | | | 2
+-+-+-+-+
| | | | | 3
+-+-+-+-+
そのため、「行を下る」たびに対角線を移動させる必要があります。
そうしないと、どの対角線が「占有」されているかという知識が、現在の行に対して正しくなくなるからです。
上記の例からわかるように、$(( ~(left|down|right )) を計算すると2#1000 となり、2行目の安全な場所は1列目のみであることがわかります。
斜めの効き筋
ビットマッププログラムのポイントは、斜めの利き筋のチェックをビット演算で行うことです。
0 1 2 3 4
*-------------
| . . . . . .
| . . . -3. . 0x02
| . . -2. . . 0x04
| . -1. . . . 0x08 (1 bit 右シフト)
| Q . . . . . 0x10 (Q の位置は 4)
| . +1. . . . 0x20 (1 bit 左シフト)
| . . +2. . . 0x40
| . . . +3. . 0x80
*-------------
この演算式の意味を理解するには、負の値がコンピュータにおける2進法ではどのように表現されているのかを知る必要があります。
負の値を2進数で表すと次のようになります。
00000011 3
00000010 2
00000001 1
00000000 0
11111111 -1
11111110 -2
11111101 -3
正の値を負の値(補数と言います)にするときは、Rをビット反転してから+1します。
00000001 1
11111110 反転
11111111 -1 (1を加える)
00000010 2
11111101 反転
11111110 -2 (1を加える)
加えるところがわかりにくいですね。
00000001 1
に1を加えると
00000010 2
さらに1を加えると
00000011 3
と、なります。
10進数の足し算と2進数のインクリメントは異なるところに注意が必要です。
ここで、 正の値22と−22をAND演算すると以下のようになります。
00010110 22
AND 11101010 -22
------------------
00000010
Nを2進法で表したときの一番下位のONビットがひとつだけ抽出される結果が得られ、極めて簡単な演算によって1ビット抽出を実現させていることが重要です。
余談ですが、
bashで2進数を10進数に変換するには以下のようにしました。
bash-3.2$ echo $(( 2#01000 ));
8
bashで10進数を2進数に変換するには以下のようにします。
bash-3.2$ bc <<<"ibase=10;obase=10;8"
1000
余談終わり。
そこで下のようなwhile文を書けば、ループが bitmap のONビットの数の回数だけループすることになり、配置可能なパターンをひとつずつ全く無駄がループがなく生成されることになります。
mask=(1<<size)-1;
bitmap=mask&~(left|down|right);
while(bitmap){
bit=bitmap&-bitmap;// 一番右のビットを取り出す
bitmap=bitmap&~bit;// 配置可能なパターンが一つずつ取り出される
board[row]=bit;// Qを配置
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);// 再帰
}
forで一行にまとめることができます。これは非常にトリッキーです。
for(unsigned int bitmap=mask&~(left|down|right);bitmap;bitmap=bitmap&~bit){
bit=bitmap&-bitmap;
board[row]=bit;
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);
}
left down right は、Qが配置されるたびに、その効き筋を足し合わせ、すべてのrowの効き筋に対応します。
再帰では、こうしたことをプログラマが意識することなく実現できるわけですが、非再帰の場合は、left down right を配列などで効き筋を覚えておく必要が出てきます。
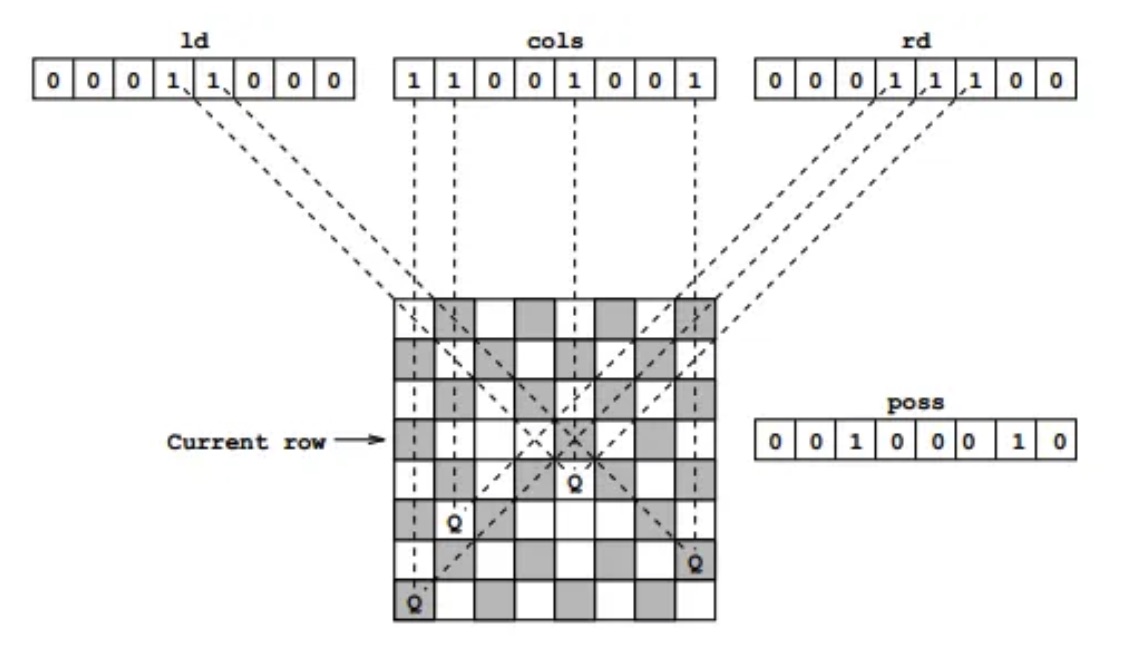
それはどうとして猛烈にわかりやすい図がありました。
CUDA ソースコード
ソースコードは以下のとおりです。
/**
*
* bash版ビットマップのC言語版のGPU/CUDA移植版
*
詳しい説明はこちらをどうぞ
https://suzukiiichiro.github.io/search/?keyword=Nクイーン問題
*
アーキテクチャの指定(なくても問題なし、あれば高速)
-arch=sm_13 or -arch=sm_61
CPUの再帰での実行
$ nvcc -O3 -arch=sm_61 01CUDA_Bitmap.cu && ./a.out -r
CPUの非再帰での実行
$ nvcc -O3 -arch=sm_61 01CUDA_Bitmap.cu && ./a.out -c
GPUのシングルスレッド
$ nvcc -O3 -arch=sm_61 01CUDA_Bitmap.cu && ./a.out -g
GPUのマルチスレッド
ビットマップ GPUノードレイヤー
$ nvcc -O3 -arch=sm_61 01CUDA_Bitmap.cu && ./a.out -n
N: Total Unique dd:hh:mm:ss.ms
4: 2 0 00:00:00:00.15
5: 10 0 00:00:00:00.00
6: 4 0 00:00:00:00.00
7: 40 0 00:00:00:00.00
8: 92 0 00:00:00:00.00
9: 352 0 00:00:00:00.00
10: 724 0 00:00:00:00.00
11: 2680 0 00:00:00:00.00
12: 14200 0 00:00:00:00.00
13: 73712 0 00:00:00:00.00
14: 365596 0 00:00:00:00.04
15: 2279184 0 00:00:00:00.21
16: 14772512 0 00:00:00:02.05
17: 95815104 0 00:00:00:19.56
18: 666090624 0 00:00:03:15.21
コメント追加
・kLayer_nodeLayer
GPUで並列実行するためのleft,right,downを作成する
kLayer_nodeLayer(size,4)
第2引数の4は4行目までnqueenを実行し、それまでのleft,down,rightをnodes配列に格納する
nodesはベクター配列で構造体でもなんでも格納できる
push_backで追加。
nodes配列は3個で1セットleft,dwon,rightの情報を同じ配列に格納する
[0]left[1]down[2]right
・bitmap_build_nodeLayer
int numSolutions = nodes.size() / 6;
3個で1セットなので/3 さらにnodesの2分の1だけ実行すればミラーになるので/6
solutions += 2*hostSolutions[i]; // Symmetry
GPUごとのTOTALを集計している。ミラー分最後に2倍する
・dim_nodeLayer
GPU並列処理
bitmap_solve_nodeLayerを再帰呼び出しし、counter(最終行までクイーンを置けると+1)をsolutionsに格納する
solutionsは配列でGPUのステップ数分ある
・bitmap_solve_ndoeLayer
down==maskが最終行までクイーンを置けた状態
ビットだとクイーンを置けない場所に1が立つ
downだとクイーンを置いた場所に1が立つ
maskは、size分1が立っているもの
n8だと11111111
downはクイーンが配置されるたびに配置された列に1が立って行くので最終行までクイーンを置くと全列に1が立った状態になりmaskと同じ内容になる
*/
#include <iostream>
#include <vector>
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <math.h>
#include <string.h>
#include <time.h>
#include <sys/time.h>
#include <cuda.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#define THREAD_NUM 96
#define MAX 27
// システムによって以下のマクロが必要であればコメントを外してください。
//#define UINT64_C(c) c ## ULL
//
// グローバル変数
unsigned long TOTAL=0;
unsigned long UNIQUE=0;
// ビットマップ 非再帰版
void bitmap_NR(unsigned int size,int row)
{
unsigned int mask=(1<<size)-1;
unsigned int bitmap[size];
unsigned int bit=0;
unsigned int left[size];
unsigned int down[size];
unsigned int right[size];
left[0]=0;
down[0]=0;
right[0]=0;
bitmap[row]=mask;
while(row>-1){
if(bitmap[row]>0){
bit=-bitmap[row]&bitmap[row];//一番右のビットを取り出す
bitmap[row]=bitmap[row]^bit;//配置可能なパターンが一つずつ取り出される
if(row==(size-1)){
TOTAL++;
row--;
}else{
unsigned int n=row++;
left[row]=(left[n]|bit)<<1;
down[row]=down[n]|bit;
right[row]=(right[n]|bit)>>1;
//クイーンが配置可能な位置を表す
bitmap[row]=mask&~(left[row]|down[row]|right[row]);
}
}else{
row--;
}
}//end while
}
// ビットマップ 再帰版
void bitmap_R(unsigned int size,unsigned int row,unsigned int left,unsigned int down, unsigned int right)
{
unsigned int mask=(1<<size)-1;
unsigned int bit=0;
if(row==size){
TOTAL++;
}else{
// クイーンが配置可能な位置を表す
for(unsigned int bitmap=mask&~(left|down|right);bitmap;bitmap=bitmap&~bit){
bit=bitmap&-bitmap;
bitmap_R(size,row+1,(left|bit)<<1,down|bit,(right|bit)>>1);
}
}
}
// クイーンの効きを判定して解を返す
__host__ __device__
long bitmap_solve_nodeLayer(int size,long left,long down,long right)
{
long mask=(1<<size)-1;
long counter = 0;
if (down==mask) { // downがすべて専有され解が見つかる
return 1;
}
long bit=0;
for(long bitmap=mask&~(left|down|right);bitmap;bitmap^=bit){
bit=-bitmap&bitmap;
counter += bitmap_solve_nodeLayer(size,(left|bit)>>1,(down|bit),(right|bit)<< 1);
}
return counter;
}
// i 番目のメンバを i 番目の部分木の解で埋める
__global__
void dim_nodeLayer(int size,long* nodes, long* solutions, int numElements)
{
int i=blockDim.x * blockIdx.x + threadIdx.x;
if(i<numElements){
solutions[i]=bitmap_solve_nodeLayer(size,nodes[3 * i],nodes[3 * i + 1],nodes[3 * i + 2]);
}
}
// 0以外のbitをカウント
int countBits_nodeLayer(long n)
{
int counter = 0;
while (n){
n &= (n - 1); // 右端のゼロ以外の数字を削除
counter++;
}
return counter;
}
// ノードをk番目のレイヤーのノードで埋める
long kLayer_nodeLayer(int size,std::vector<long>& nodes, int k, long left, long down, long right)
{
long counter=0;
long mask=(1<<size)-1;
// すべてのdownが埋まったら、解決策を見つけたことになる。
if (countBits_nodeLayer(down) == k) {
nodes.push_back(left);
nodes.push_back(down);
nodes.push_back(right);
return 1;
}
long bit=0;
for(long bitmap=mask&~(left|down|right);bitmap;bitmap^=bit){
bit=-bitmap&bitmap;
// 解を加えて対角線をずらす
counter+=kLayer_nodeLayer(size,nodes,k,(left|bit)>>1,(down|bit),(right|bit)<<1);
}
return counter;
}
// k 番目のレイヤのすべてのノードを含むベクトルを返す。
std::vector<long> kLayer_nodeLayer(int size,int k)
{
std::vector<long> nodes{};
kLayer_nodeLayer(size,nodes, k, 0, 0, 0);
return nodes;
}
// 【GPU ビットマップ】ノードレイヤーの作成
void bitmap_build_nodeLayer(int size)
{
//int size=16;
// ツリーの3番目のレイヤーにあるノード
//(それぞれ連続する3つの数字でエンコードされる)のベクトル。
// レイヤー2以降はノードの数が均等なので、対称性を利用できる。
// レイヤ4には十分なノードがある(N16の場合、9844)。
std::vector<long> nodes = kLayer_nodeLayer(size,4);
// デバイスにはクラスがないので、
// 最初の要素を指定してからデバイスにコピーする。
size_t nodeSize = nodes.size() * sizeof(long);
long* hostNodes = (long*)malloc(nodeSize);
hostNodes = &nodes[0];
long* deviceNodes = NULL;
cudaMalloc((void**)&deviceNodes, nodeSize);
cudaMemcpy(deviceNodes, hostNodes, nodeSize, cudaMemcpyHostToDevice);
// デバイス出力の割り当て
long* deviceSolutions = NULL;
// 必要なのはノードの半分だけで、各ノードは3つの整数で符号化される。
int numSolutions = nodes.size() / 6;
size_t solutionSize = numSolutions * sizeof(long);
cudaMalloc((void**)&deviceSolutions, solutionSize);
// CUDAカーネルを起動する。
int threadsPerBlock = 256;
int blocksPerGrid = (numSolutions + threadsPerBlock - 1) / threadsPerBlock;
dim_nodeLayer <<<blocksPerGrid, threadsPerBlock >>> (size,deviceNodes, deviceSolutions, numSolutions);
// 結果をホストにコピー
long* hostSolutions = (long*)malloc(solutionSize);
cudaMemcpy(hostSolutions, deviceSolutions, solutionSize, cudaMemcpyDeviceToHost);
// 部分解を加算し、結果を表示する。
long solutions = 0;
for (long i = 0; i < numSolutions; i++) {
solutions += 2*hostSolutions[i]; // Symmetry
}
// 出力
//std::cout << "We have " << solutions << " solutions on a " << size << " by " << size << " board." << std::endl;
TOTAL=solutions;
//return 0;
}
// CUDA 初期化
bool InitCUDA()
{
int count;
cudaGetDeviceCount(&count);
if(count==0){fprintf(stderr,"There is no device.\n");return false;}
int i;
for(i=0;i<count;i++){
struct cudaDeviceProp prop;
if(cudaGetDeviceProperties(&prop,i)==cudaSuccess){if(prop.major>=1){break;} }
}
if(i==count){fprintf(stderr,"There is no device supporting CUDA 1.x.\n");return false;}
cudaSetDevice(i);
return true;
}
//メイン
int main(int argc,char** argv)
{
bool cpu=false,cpur=false,gpu=false,gpuNodeLayer=false;
int argstart=2;
if(argc>=2&&argv[1][0]=='-'){
if(argv[1][1]=='c'||argv[1][1]=='C'){cpu=true;}
else if(argv[1][1]=='r'||argv[1][1]=='R'){cpur=true;}
else if(argv[1][1]=='c'||argv[1][1]=='C'){cpu=true;}
else if(argv[1][1]=='g'||argv[1][1]=='G'){gpu=true;}
else if(argv[1][1]=='n'||argv[1][1]=='N'){gpuNodeLayer=true;}
else{ gpuNodeLayer=true; } //デフォルトをgpuとする
argstart=2;
}
if(argc<argstart){
printf("Usage: %s [-c|-g|-r|-s] n steps\n",argv[0]);
printf(" -r: CPU 再帰\n");
printf(" -c: CPU 非再帰\n");
printf(" -g: GPU 再帰\n");
printf(" -n: GPU ノードレイヤー\n");
}
if(cpur){ printf("\n\nビットマップ 再帰 \n"); }
else if(cpu){ printf("\n\nビットマップ 非再帰 \n"); }
else if(gpu){ printf("\n\nビットマップ GPU\n"); }
else if(gpuNodeLayer){ printf("\n\nビットマップ GPUノードレイヤー \n"); }
if(cpu||cpur){
int min=4;
int targetN=17;
struct timeval t0;
struct timeval t1;
printf("%s\n"," N: Total Unique dd:hh:mm:ss.ms");
for(int size=min;size<=targetN;size++){
TOTAL=UNIQUE=0;
gettimeofday(&t0, NULL);//計測開始
if(cpur){ //再帰
bitmap_R(size,0,0,0,0);
}
if(cpu){ //非再帰
bitmap_NR(size,0);
}
//
gettimeofday(&t1, NULL);//計測終了
int ss;int ms;int dd;
if(t1.tv_usec<t0.tv_usec) {
dd=(t1.tv_sec-t0.tv_sec-1)/86400;
ss=(t1.tv_sec-t0.tv_sec-1)%86400;
ms=(1000000+t1.tv_usec-t0.tv_usec+500)/10000;
}else {
dd=(t1.tv_sec-t0.tv_sec)/86400;
ss=(t1.tv_sec-t0.tv_sec)%86400;
ms=(t1.tv_usec-t0.tv_usec+500)/10000;
}//end if
int hh=ss/3600;
int mm=(ss-hh*3600)/60;
ss%=60;
printf("%2d:%16ld%17ld%12.2d:%02d:%02d:%02d.%02d\n",
size,TOTAL,UNIQUE,dd,hh,mm,ss,ms);
} //end for
}//end if
if(gpu||gpuNodeLayer){
if(!InitCUDA()){return 0;}
/* int steps=24576; */
int min=4;
int targetN=21;
struct timeval t0;
struct timeval t1;
printf("%s\n"," N: Total Unique dd:hh:mm:ss.ms");
for(int size=min;size<=targetN;size++){
gettimeofday(&t0,NULL); // 計測開始
if(gpu){
TOTAL=UNIQUE=0;
TOTAL=bitmap_solve_nodeLayer(size,0,0,0); //ビットマップ
}else if(gpuNodeLayer){
TOTAL=UNIQUE=0;
bitmap_build_nodeLayer(size); // ビットマップ
}
gettimeofday(&t1,NULL); // 計測終了
int ss;int ms;int dd;
if (t1.tv_usec<t0.tv_usec) {
dd=(int)(t1.tv_sec-t0.tv_sec-1)/86400;
ss=(t1.tv_sec-t0.tv_sec-1)%86400;
ms=(1000000+t1.tv_usec-t0.tv_usec+500)/10000;
} else {
dd=(int)(t1.tv_sec-t0.tv_sec)/86400;
ss=(t1.tv_sec-t0.tv_sec)%86400;
ms=(t1.tv_usec-t0.tv_usec+500)/10000;
}//end if
int hh=ss/3600;
int mm=(ss-hh*3600)/60;
ss%=60;
printf("%2d:%13ld%16ld%4.2d:%02d:%02d:%02d.%02d\n",
size,TOTAL,UNIQUE,dd,hh,mm,ss,ms);
}//end for
}//end if
return 0;
}
CUDA 実行結果
GPUのマルチスレッド
ビットマップ GPUノードレイヤー
$ nvcc -O3 -arch=sm_61 01CUDA_Bitmap.cu && ./a.out -n
N: Total Unique dd:hh:mm:ss.ms
4: 2 0 00:00:00:00.15
5: 10 0 00:00:00:00.00
6: 4 0 00:00:00:00.00
7: 40 0 00:00:00:00.00
8: 92 0 00:00:00:00.00
9: 352 0 00:00:00:00.00
10: 724 0 00:00:00:00.00
11: 2680 0 00:00:00:00.00
12: 14200 0 00:00:00:00.00
13: 73712 0 00:00:00:00.00
14: 365596 0 00:00:00:00.04
15: 2279184 0 00:00:00:00.21
16: 14772512 0 00:00:00:02.05
17: 95815104 0 00:00:00:19.56
18: 666090624 0 00:00:03:15.21
次回はミラーに行きます!
参考リンク
以下の詳細説明を参考にしてください。
【参考リンク】Nクイーン問題 過去記事一覧
【Github】エイト・クイーンのソース置き場 BashもJavaもPythonも!
Nクイーン問題(50)第七章 マルチプロセス Python編
https://suzukiiichiro.github.io/posts/2023-06-21-04-n-queens-suzuki/
Nクイーン問題(49)第七章 マルチスレッド Python編
https://suzukiiichiro.github.io/posts/2023-06-21-03-n-queens-suzuki/
Nクイーン問題(48)第七章 シングルスレッド Python編
https://suzukiiichiro.github.io/posts/2023-06-21-02-n-queens-suzuki/
Nクイーン問題(47)第七章 クラス Python編
https://suzukiiichiro.github.io/posts/2023-06-21-01-n-queens-suzuki/
Nクイーン問題(46)第七章 ステップNの実装 Python編
https://suzukiiichiro.github.io/posts/2023-06-16-02-n-queens-suzuki/
Nクイーン問題(45)第七章 キャリーチェーン Python編
https://suzukiiichiro.github.io/posts/2023-06-16-01-n-queens-suzuki/
Nクイーン問題(44)第七章 対象解除法 Python編
https://suzukiiichiro.github.io/posts/2023-06-14-02-n-queens-suzuki/
Nクイーン問題(43)第七章 ミラー Python編
https://suzukiiichiro.github.io/posts/2023-06-14-01-n-queens-suzuki/
Nクイーン問題(42)第七章 ビットマップ Python編
https://suzukiiichiro.github.io/posts/2023-06-13-05-n-queens-suzuki/
Nクイーン問題(41)第七章 配置フラグ Python編
https://suzukiiichiro.github.io/posts/2023-06-13-04-n-queens-suzuki/
Nクイーン問題(40)第七章 バックトラック Python編
https://suzukiiichiro.github.io/posts/2023-06-13-03-n-queens-suzuki/
Nクイーン問題(39)第七章 バックトラック準備編 Python編
https://suzukiiichiro.github.io/posts/2023-06-13-02-n-queens-suzuki/
Nクイーン問題(38)第七章 ブルートフォース Python編
https://suzukiiichiro.github.io/posts/2023-06-13-01-n-queens-suzuki/
Nクイーン問題(37)第六章 C言語移植 その17 pthread並列処理完成
https://suzukiiichiro.github.io/posts/2023-05-30-17-n-queens-suzuki/
Nクイーン問題(36)第六章 C言語移植 その16 pthreadの実装
https://suzukiiichiro.github.io/posts/2023-05-30-16-n-queens-suzuki/
Nクイーン問題(35)第六章 C言語移植 その15 pthread実装直前版完成
https://suzukiiichiro.github.io/posts/2023-05-30-15-n-queens-suzuki/
Nクイーン問題(34)第六章 C言語移植 その14
https://suzukiiichiro.github.io/posts/2023-05-30-14-n-queens-suzuki/
Nクイーン問題(33)第六章 C言語移植 その13
https://suzukiiichiro.github.io/posts/2023-05-30-13-n-queens-suzuki/
Nクイーン問題(32)第六章 C言語移植 その12
https://suzukiiichiro.github.io/posts/2023-05-30-12-n-queens-suzuki/
Nクイーン問題(31)第六章 C言語移植 その11
https://suzukiiichiro.github.io/posts/2023-05-30-11-n-queens-suzuki/
Nクイーン問題(30)第六章 C言語移植 その10
https://suzukiiichiro.github.io/posts/2023-05-30-10-n-queens-suzuki/
Nクイーン問題(29)第六章 C言語移植 その9
https://suzukiiichiro.github.io/posts/2023-05-30-09-n-queens-suzuki/
Nクイーン問題(28)第六章 C言語移植 その8
https://suzukiiichiro.github.io/posts/2023-05-30-08-n-queens-suzuki/
Nクイーン問題(27)第六章 C言語移植 その7
https://suzukiiichiro.github.io/posts/2023-05-30-07-n-queens-suzuki/
Nクイーン問題(26)第六章 C言語移植 その6
https://suzukiiichiro.github.io/posts/2023-05-30-06-n-queens-suzuki/
Nクイーン問題(25)第六章 C言語移植 その5
https://suzukiiichiro.github.io/posts/2023-05-30-05-n-queens-suzuki/
Nクイーン問題(24)第六章 C言語移植 その4
https://suzukiiichiro.github.io/posts/2023-05-30-04-n-queens-suzuki/
Nクイーン問題(23)第六章 C言語移植 その3
https://suzukiiichiro.github.io/posts/2023-05-30-03-n-queens-suzuki/
Nクイーン問題(22)第六章 C言語移植 その2
https://suzukiiichiro.github.io/posts/2023-05-30-02-n-queens-suzuki/
Nクイーン問題(21)第六章 C言語移植 その1
N-Queens問://suzukiiichiro.github.io/posts/2023-05-30-01-n-queens-suzuki/
Nクイーン問題(20)第五章 並列処理
https://suzukiiichiro.github.io/posts/2023-05-23-02-n-queens-suzuki/
Nクイーン問題(19)第五章 キャリーチェーン
https://suzukiiichiro.github.io/posts/2023-05-23-01-n-queens-suzuki/
Nクイーン問題(18)第四章 エイト・クイーンノスタルジー
https://suzukiiichiro.github.io/posts/2023-04-25-01-n-queens-suzuki/
Nクイーン問題(17)第四章 偉人のソースを読む「N24を発見 Jeff Somers」
https://suzukiiichiro.github.io/posts/2023-04-21-01-n-queens-suzuki/
Nクイーン問題(16)第三章 対象解除法 ソース解説
https://suzukiiichiro.github.io/posts/2023-04-18-01-n-queens-suzuki/
Nクイーン問題(15)第三章 対象解除法 ロジック解説
https://suzukiiichiro.github.io/posts/2023-04-13-02-nqueens-suzuki/
Nクイーン問題(14)第三章 ミラー
https://suzukiiichiro.github.io/posts/2023-04-13-01-nqueens-suzuki/
Nクイーン問題(13)第三章 ビットマップ
https://suzukiiichiro.github.io/posts/2023-04-05-01-nqueens-suzuki/
Nクイーン問題(12)第二章 まとめ
https://suzukiiichiro.github.io/posts/2023-03-17-02-n-queens-suzuki/
Nクイーン問題(11)第二章 配置フラグの再帰・非再帰
https://suzukiiichiro.github.io/posts/2023-03-17-01-n-queens-suzuki/
Nクイーン問題(10)第二章 バックトラックの再帰・非再帰
https://suzukiiichiro.github.io/posts/2023-03-16-01-n-queens-suzuki/
Nクイーン問題(9)第二章 ブルートフォースの再帰・非再帰
https://suzukiiichiro.github.io/posts/2023-03-14-01-n-queens-suzuki/
Nクイーン問題(8)第一章 まとめ
https://suzukiiichiro.github.io/posts/2023-03-09-01-n-queens-suzuki/
Nクイーン問題(7)第一章 ブルートフォース再び
https://suzukiiichiro.github.io/posts/2023-03-08-01-n-queens-suzuki/
Nクイーン問題(6)第一章 配置フラグ
https://suzukiiichiro.github.io/posts/2023-03-07-01-n-queens-suzuki/
Nクイーン問題(5)第一章 進捗表示テーブルの作成
https://suzukiiichiro.github.io/posts/2023-03-06-01-n-queens-suzuki/
Nクイーン問題(4)第一章 バックトラック
https://suzukiiichiro.github.io/posts/2023-02-21-01-n-queens-suzuki/
Nクイーン問題(3)第一章 バックトラック準備編
https://suzukiiichiro.github.io/posts/2023-02-14-03-n-queens-suzuki/
Nクイーン問題(2)第一章 ブルートフォース
https://suzukiiichiro.github.io/posts/2023-02-14-02-n-queens-suzuki/
Nクイーン問題(1)第一章 エイトクイーンについて
https://suzukiiichiro.github.io/posts/2023-02-14-01-n-queens-suzuki/